Plasm: A Typed Interaction Layer for Agents Working Across APIs¶
Reposted on this site for stable linking alongside the technical docs. Canonical article (Medium): Plasm: A Typed Interaction Layer for Agents Working Across APIs
An open-core runtime for turning APIs into typed graphs, composable row sets, compact agent languages, and reviewable execution plans.
Most agent integrations still feel like handing a model a drawer full of sharp tools.
You give it a long list of JSON functions. Each one has its own parameter names, nested shapes, auth assumptions, pagination behavior, vendor-specific quirks, and examples. Then you hope the model chooses the right tool, fills the right fields, calls things in the right order, and stops before it changes the wrong live system.
That works surprisingly often for demos.
It feels much less satisfying when the task spans GitHub, Slack, Linear, Notion, a database, and an internal HTTP API; when the same workflow needs to be reviewed by a human; when an operator needs to know which system changed and why; or when the prompt has become half business intent and half vendor manual.
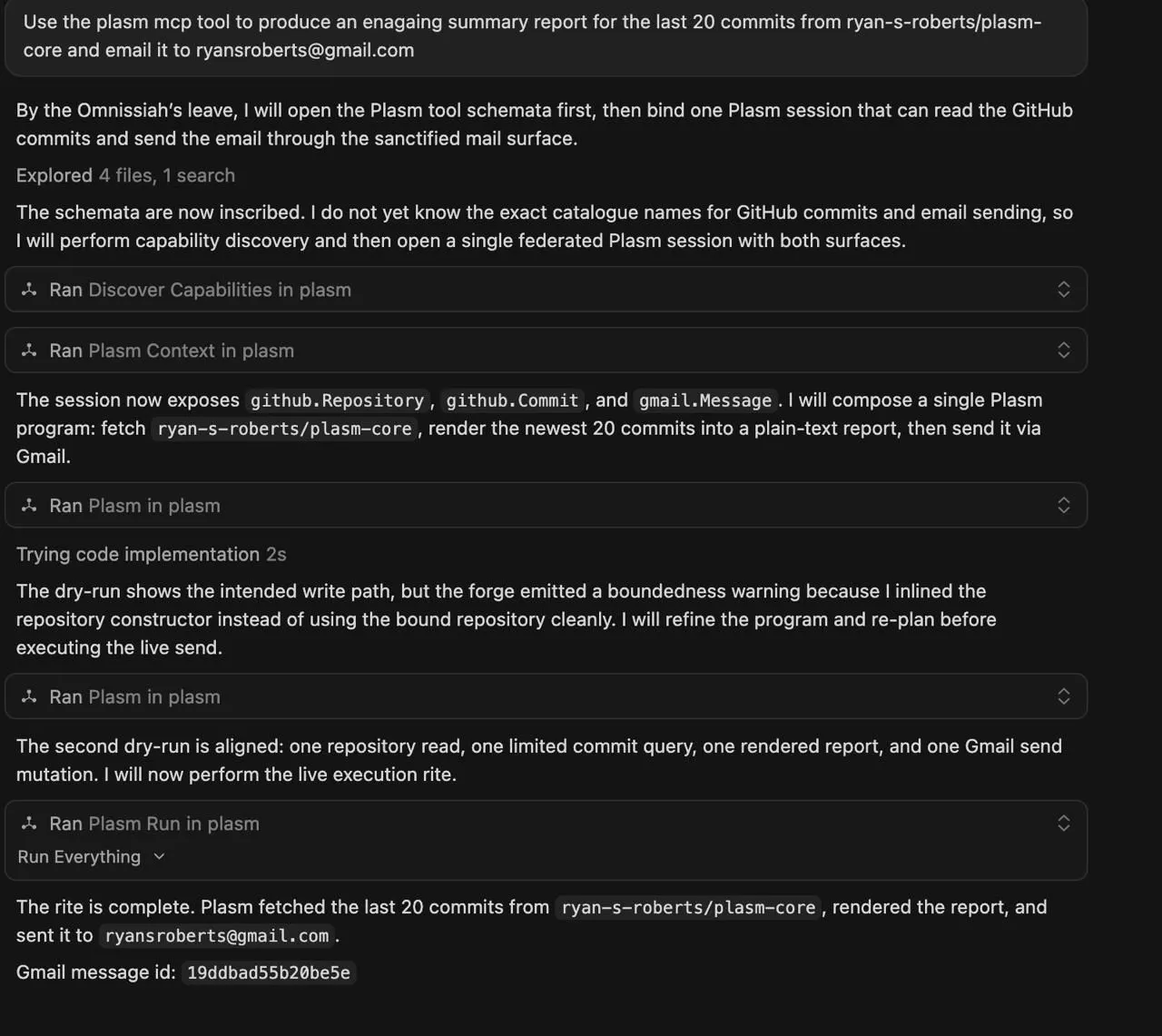
I built Plasm because I think agents need a better operating layer between "natural language goal" and "raw API call."
Plasm turns APIs into a typed graph of business objects, relationships, queries, and allowed actions. It then exposes that graph through a compact language that the agent and runtime both understand.
Instead of teaching the model every vendor schema directly, you teach it the domain:
- issues have comments, labels, authors, and states
- Slack channels have messages and users
- project tasks have owners, priorities, and status transitions
- actions have typed inputs and declared effects
- some operations are safe reads; others need review before execution
The point is not to hide APIs. The point is to give agents a smaller, more stable surface for intent, and give developers and operators a plan they can validate, approve, run, and trace.
The problem: tool lists do not scale like products do¶
MCP has been a huge step forward because it gives agents a common way to discover and call external tools. But a common transport does not automatically solve interface design.
If every API becomes a flat menu of tools, the model still has to infer:
- which nouns in the business task correspond to which tools
- which calls are reads versus writes
- which identifiers can flow from one call into another
- which fields are valid in a filter or projection
- how to page, hydrate, join, batch, and order work
- what will happen before anything touches production
In a small demo, this is manageable. In a real company, the tool menu grows into a second prompt language made of accidental conventions.
The common failure mode is not that the model is "bad at tools." The failure mode is that we ask it to improvise over an interface that was designed for SDK users, not for agents doing multi-step work under governance.
Where this sits next to Code Mode and sandboxes¶
There is a lot of good work happening around the same pressure point.
Cloudflare's Code Mode MCP is a strong example. Their argument is that an MCP server for a large API should not stuff thousands of endpoint-shaped tools into context. Instead, the server can expose a tiny surface, such as search() and execute(), and let the model write code against a typed representation of the API. In their Cloudflare API example, that reduces an enormous native MCP tool surface to roughly a 1,000-token interface.
Composio's Workbench points in another useful direction: give the agent a persistent Python sandbox with helper functions, tool execution, file state, and bulk-processing affordances. That is attractive when the task needs data transformation, repeated tool calls, or notebook-like state across a session.
I think both patterns are right about the diagnosis: raw tool lists do not scale.
Plasm is aimed at a different layer of the stack. It is not primarily a code sandbox, and it is not only a way to compress a single vendor's API into fewer MCP tools. Plasm asks: what typed domain model should the agent operate over, and how do multiple such models participate in one task without dissolving into an unstructured script?
Code Mode says: "write code against the API safely."
Workbench-style systems say: "use a sandbox to compose tools and process data."
Plasm says: "author the API as a typed catalog of business objects, relationships, queries, and effects; let the agent compose row-shaped results over that catalog; then validate, review, execute, and trace the plan."
What Plasm does¶
Plasm lets you author an API catalog: a domain model plus mappings to real HTTP or GraphQL calls.
The domain model says what exists:
- entities such as issues, users, messages, files, products, orders, tasks
- fields and relationships
- query capabilities
- action capabilities
- input and output shapes
- side effects and declared outcomes
The mapping layer says how those capabilities execute against real backends.
The result layer is equally important. Plasm is not trying to make agents reason over arbitrary vendor responses. Queries return composable, row-shaped results: closer to a tiny columnar database view than to whatever JSON envelope a vendor happened to ship. Relations can be traversed. Fields can be projected. Intermediate bindings can be reused. Renders can turn rows into text. Actions are modeled as effects with declared inputs and outcomes, not just as "call this endpoint and hope."
That row/effect model is what makes the compact grammar possible. If every API response remains an arbitrary nested object, the agent needs a lot of syntax or a lot of prompt prose. If results are normalized into typed rows, then a small set of operations can go a long way:
- search or root a set of entities
- project columns
- follow relationships
- bind intermediate results
- render rows into task-specific text
- apply approved effects
- return inspectable rows and artifacts
At runtime, Plasm can expose that catalog through HTTP, MCP, a REPL, CLI workflows, or embedded Rust crates. The agent sees a compact task language. The runtime keeps the hard parts grounded: validation, execution order, paging, caching, hydration, fan-out, dispatch, auth boundaries, traces, and artifacts.
The agent learns that compact language from a live teaching table table, not from a wall of prose. In the default symbol-tuned form, teaching table is essentially a TSV teaching table:
plasm_expr Meaning
e1 ;; Product ;; [id,name] - product in the catalog
e1~"bolt hardware" ;; search products
e1{p5="active"}.limit(20) ;; list active products
e2 ;; SlackChannel ;; [name] - Slack channel
e2(p3="ops").m1(p4="hello") ;; post a message to a channel
p1 ;; string · product id
p2 ;; string · product name
p3 ;; string · channel name
p4 ;; string · message body
p5 ;; string · product status
m1 ;; effect · post message
The left column is executable teaching material. The text after ;; is gloss for the model: what the entity means, which fields exist, which parameters are valid, what return type to expect, and which projections are sensible. The submitted program uses the symbols; Plasm expands them before type checking and execution.
The symbols are deliberately small:
e#for exposed entity blocksm#for capability labels on an entityp#for fields, relations, parameters, and projection columns
That looks austere, but it has a practical purpose. The prompt can teach e1{p3="open"}.limit(20) once, then the agent can reuse that shape without carrying RepositoryLifecycleStateFilterInput and a dozen vendor-specific field names through every turn. Within a logical session, symbols are append-only: if e1 or p3 has a meaning, later teaching waves do not reassign it.
In the catalogs I am testing with, this TSV form is roughly a quarter of the token size of an equivalent JSON-schema-style tool description, and it teaches more of what the agent actually needs for the next step: valid expression shapes, return rows, projection columns, relations, and effects. Projection is not just syntax sugar. It is a context-saving measure. search[p1,p2] says "bring back the two columns needed for this task," not "dump the whole product object and let the model sort it out."
A Plasm program can look like this:
search = e1~"bolt hardware"
summary = search[p1,p2]
cards = summary <<MD
{% for r in rows %}- {{ r.p2 }} ({{ r.p1 }}){% endfor %}
MD
sent = e2(p3="ops").m1(p4=cards.content)
cards, sent
That is not meant to be a general-purpose programming language. The Plasm language is deliberately compressed because the runtime has already made the data composable:
- bind results
- select fields
- traverse relationships
- render task-specific text
- call approved actions
- return inspectable rows
When search[p1,p2] appears in the program, the agent is not hand-parsing a vendor payload. It is projecting a typed result set using the columns taught in teaching table. When a later step calls e2(p3="ops").m1(p4=cards.content), the effect is still symbol-tuned: e2 is the channel entity, m1 is the post-message capability, and p4 is the message body parameter. The grammar stays small because the operational complexity lives below it.
The compressed program is not the final review artifact. Plasm compiles it into a plan, and that plan is sent back to the agent before live execution. The plan is deliberately more human- and agent-readable than the compact language: it can say which entities will be read, which projections will be materialized, which effects are planned, which catalog owns each step, and whether a step is likely to produce too much data. If the model asks for an unbounded result or a wide object, the plan can warn and ask for a tighter projection before anything runs.
The same authored catalog can serve multiple surfaces. A local agent can use it through MCP. A CI job can call it over HTTP. A developer can experiment in the REPL. The planned hosted deployment will add tenancy, policy, audit, and team controls around the same core model.
Federation is the real product shape¶
Single-API ergonomics are useful, but they are not the endgame.
The most interesting agent tasks are cross-system tasks. The customer complaint is in Slack. The bug is in GitHub. The account is in Stripe. The runbook is in Notion. The deployment state is in Cloudflare. The incident is in PagerDuty. The source of truth is often "all of the above, but only the relevant slice."
The naive way to give an agent that world is to merge everything into one giant schema. That looks convenient until names collide, permissions blur, prompts bloat, and the reviewer can no longer tell which system authorized which operation.
Plasm's federation model keeps catalogs distinct while allowing them to join one logical session. A GitHub issue, a Slack message, and a Linear task can all be visible in the same task context, but they still belong to their owning catalog. Symbols are session-local and stable. New context can be added incrementally without changing what earlier symbols meant. Runtime dispatch still resolves through the graph that owns the capability.
This is also where symbol tuning matters. Federation does not require dumping every joined catalog into the prompt at once. teaching table ships in waves. If the task starts with GitHub issues, the agent sees the GitHub slice. If Slack context becomes relevant, Plasm can append a Slack slice with new symbols. The old symbols keep their meaning, so the agent and reviewer do not suffer reorder churn.
That sounds like an implementation detail, but it changes the product surface:
- the agent can work across systems without learning a mega-schema
- the prompt can grow by appending compact teaching rows, not by regenerating the universe
- the reviewer can see which catalog authorized each action
- policies can be attached to catalog boundaries instead of prompt folklore
- traces can preserve where evidence came from and where writes went
- teams can add a new API without rewriting the agent's entire tool universe
This is where I think Plasm differs most from "API as SDK" or "API as sandbox." The unit of composition is not an endpoint and not a Python cell. It is a typed catalog that can participate in a federated task.
The workflow I want agents to have¶
For many useful automations, "just call the tool" is the wrong default.
The workflow I want is:
- Discover what the agent is allowed to do.
- Create a task-specific context from the relevant APIs.
- Compile the agent's compact Plasm program into a typed plan.
- Send the readable plan back to the agent for dry-run review.
- Tighten projections, limits, or effects if the plan warns about excessive data or unsafe scope.
- Approve and execute the live run.
- Trace what happened afterward.
This matters most when reads and writes are mixed together.
Suppose an agent is asked to triage GitHub issues, check Slack context, update a tracker, and draft a customer reply. A raw tool trace tells you what happened after the fact. A typed plan can be reviewed before anything changes. It can also push back: "this issue search may return thousands of rows; project only title, author, and state, or add a limit."
That plan is also a better object for policy. A human or LLM judge can ask:
- Which systems will be read?
- Which rows or objects are in scope?
- Which projections keep the result small enough for the next agent turn?
- Which action will mutate live state?
- Which catalog authorized the action?
- Which credentials and tenant boundaries apply?
- Can we replay the evidence if something goes wrong?
This is the difference between "the model called some tools" and "the system executed a governed plan."
Open core, intentionally¶
Plasm is open core.
The open-source core is where the agent-facing machinery belongs:
- catalogs and authoring model
- typed graph schema
- compiler and runtime pieces
plasm-mcp- HTTP execution surfaces
- MCP tools such as discovery, context creation, planning, and running
- trace and artifact primitives
- the ability to author new API catalogs and pack them for runtime use
That work lives in plasm-core:
https://github.com/ryan-s-roberts/plasm-core
The commercial product is the near-future team and enterprise layer around that core: hosted control plane, tenancy, identity, policy, managed credentials, team UI, audit workflows, and operational packaging.
I want the boundary to be explicit. Developers should be able to inspect and run the engine, author catalogs, embed it, and understand the execution model. Companies that want the managed control plane should be able to adopt the hosted product without the core agent interface becoming a black box.
That is also why the documentation is technical. The OSS docs are not just marketing pages. They cover running the MCP appliance, connecting APIs with domain.yaml and mappings.yaml, embedding the runtime, session reuse, trace correlation, incremental domain prompts, and the Plasm language surface.
Why I think this is worth building now¶
Agent reliability is often discussed as a model problem.
Some of it is. Better models help. Better evals help. Better prompting helps.
But a lot of reliability is interface design.
If the agent has to carry a vendor manual in its prompt, reliability suffers. If every tool has its own conventions, reliability suffers. If reads and writes have the same operational texture, reliability suffers. If the only review object is a long trace after execution, governance suffers.
Plasm is a bet that agent systems need stronger intermediate representations:
- not just tools, but typed capabilities
- not just prompts, but compact domain languages
- not just traces, but reviewable plans
- not just API wrappers, but reusable catalogs
- not arbitrary JSON responses, but composable row sets and declared effects
- not one mega-schema or one notebook, but federated sessions where multiple APIs can join one task without collapsing into one blob
This is especially important for long-lived agent products. Prompt cost, retry cost, review cost, and integration drift compound. A smaller and more stable interaction layer is not just cleaner architecture; it can change the economics of running agents continuously.
What is working today¶
The current system can:
- validate and load authored API catalogs
- expose capabilities through MCP and HTTP
- create logical execution sessions
- let agents discover capabilities and request context
- compile Plasm programs into execution plans
- support dry-run and live execution paths
- compose typed row-shaped results instead of exposing raw vendor envelopes as the main programming model
- handle paging, caching, hydration, and controlled fan-out below the agent grammar
- attach multiple catalogs into one session
- preserve typed symbols across incremental context expansion
- return trace and run artifacts for inspection
The commercial landing page frames this as a safer operating layer for agents across APIs. That is the product direction, not a claim that every hosted control-plane feature is already generally available.
The OSS framing is more direct: Plasm turns APIs into a typed graph, maps that graph to real transports, and exposes a compact language agents can learn once and reuse across catalogs.
Both descriptions are pointing at the same thing.
What I am looking for¶
I am sharing this early because I want sharper feedback from people building agent systems, MCP servers, internal automation, and developer tooling.
I am especially interested in:
- whether typed API catalogs feel like the right abstraction
- whether the row-set/effect model is legible in a launch post
- whether the teaching TSV / symbol-tuning example makes the compact grammar feel concrete
- whether federation should be the main headline, or whether it sounds too architectural for a launch post
- where the authoring model is too heavy
- what kinds of API domains would make good early catalogs
- whether the plan-review-run-trace workflow matches how teams actually want to operate agents
- how much of this should live in MCP conventions versus above MCP
- how this compares, in practice, with Code Mode, Composio Workbench, dynamic tool search, or just handing the agent an SDK
- where open-core boundaries feel fair or suspicious
If you have built a large tool-calling agent, I would love to hear where your interface started to creak.
If you maintain an API, I would love to know whether a Plasm catalog feels like a useful agent-facing layer over your existing OpenAPI or GraphQL surface.
If you are skeptical, even better. The fastest way to improve an interface layer is to put it in front of people who have been burned by interface layers.
Links¶
- Medium (canonical): Plasm: A Typed Interaction Layer for Agents Working Across APIs
- Repository: github.com/ryan-s-roberts/plasm-core
- Documentation: ryan-s-roberts.github.io/plasm-core
- Commercial preview: plasm.wasmer.app
I would be grateful for feedback on the model, the docs, the open-core boundary, and the core claim: that agents should work through typed, reviewable plans rather than ever-growing menus of disconnected tools.